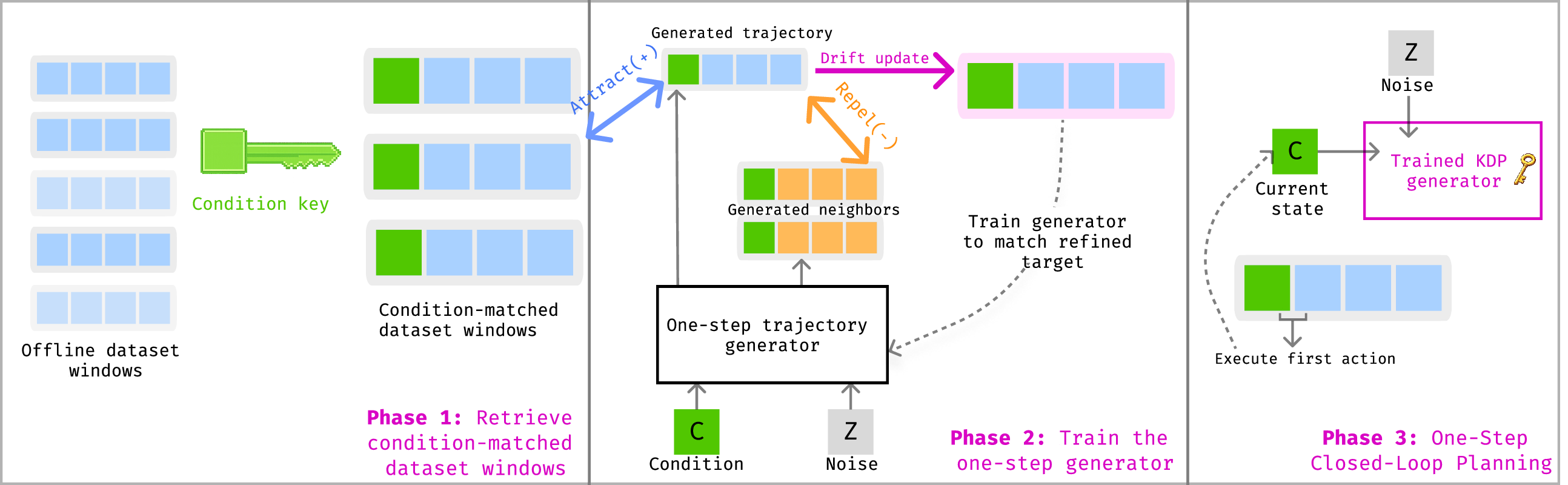
Keyed Drifting Policies (KDP) is a simple and effective one-step trajectory planning method for offline RL and robotics, designed to recover diffusion-like planning behavior without the expensive iterative denoising loop.
KDP is conditioning-aware. Rather than matching trajectories in the full high-dimensional window space, KDP forms neighborhoods in a compact key space aligned with the condition (for example, the current state), which avoids collapse toward average, inert trajectories.
KDP is trained by drift-based refinement. It pulls generated trajectories toward condition-matched dataset windows and repels them from nearby generated samples, using a stop-gradient drifted target to amortize refinement into the generator during training.
KDP is fast and performant. At inference, it generates a full trajectory window in a single forward pass, preserving multimodal candidate planning while substantially reducing planning latency compared with diffusion sampling.
Challenge
Diffusion trajectory planners are expressive but too slow for real-time control.
In receding-horizon planning, each control step may require \(T\) sequential denoising steps for every candidate trajectory, so latency grows quickly and can make closed-loop planning brittle under tight compute budgets.
One-step conditional trajectory generation is easy to get wrong.
If we naively match trajectories in the full high-dimensional window space, distances are dominated by unconstrained future dimensions, which pulls samples toward average trajectories, collapses diversity, and leads to near-static behavior instead of useful condition-consistent plans.
Key observation: Conditional trajectory generation requires a conditioning-aware notion of neighborhood.
Abstract
Diffusion-based trajectory planners can synthesize rich, multimodal action sequences for offline reinforcement learning, but their iterative denoising incurs substantial inference-time cost, making closed-loop planning slow under tight compute budgets. We study the problem of achieving diffusion-like trajectory planning behavior with one-step inference, while retaining the ability to sample diverse candidate plans and condition on the current state in a receding-horizon control loop. Our key observation is that conditional trajectory generation fails under naïve distribution-matching objectives when the similarity measure used to align generated trajectories with the dataset is dominated by unconstrained future dimensions. In practice, this causes attraction toward average trajectories, collapses action diversity, and yields near-static behavior. Our key insight is that conditional generative planning requires a conditioning-aware notion of neighborhood: trajectory updates should be computed using distances in a compact key space that reflects the condition, while still applying updates in the full trajectory space. Building on this, we introduce Keyed Drifting Policies (KDP), a one-step trajectory generator trained with a drift-field objective that attracts generated trajectories toward condition-matched dataset windows and repels them from nearby generated samples, using a stop-gradient drifted target to amortize iterative refinement into training. At inference, the resulting policy produces a full trajectory window in a single forward pass. Across standard RL benchmarks and real-time hardware deployments, KDP achieves strong performance with one-step inference and substantially lower planning latency than diffusion sampling.
 Amortizing Trajectory Diffusion
Amortizing Trajectory Diffusion